
Reducción de dimensión: Análisis Discriminante de Fisher
Contents
Reducción de dimensión: Análisis Discriminante de Fisher¶
Julián D. Arias Londoño¶
Profesor Asociado
Departamento de Ingeniería de Sistemas
Universidad de Antioquia, Medellín, Colombia
julian.ariasl@udea.edu.co
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
Supongamos el siguiente conjunto de muestras en un problema de clasificación de dos clases:
np.random.seed(1)
X = np.dot(np.random.random(size=(2, 2)), np.random.normal(size=(2, 200))*4).T
X2 = np.dot(np.random.random(size=(2, 2)), np.random.normal(size=(2, 200))).T + np.array([0,4])
X3 = np.r_[X,X2]
Y = np.r_[np.ones(200),np.zeros(200)]
# center data on 0,0
X3=X3-np.mean(X3, axis=0)
plt.figure(figsize=(8,8))
plt.scatter(X3[:,0], X3[:,1], c=Y)
plt.xlabel('variable 1')
plt.ylabel('variable 2')
<matplotlib.collections.PathCollection at 0x7f1902f09610>
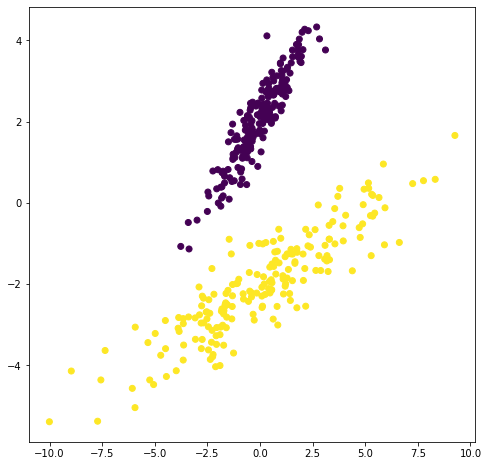
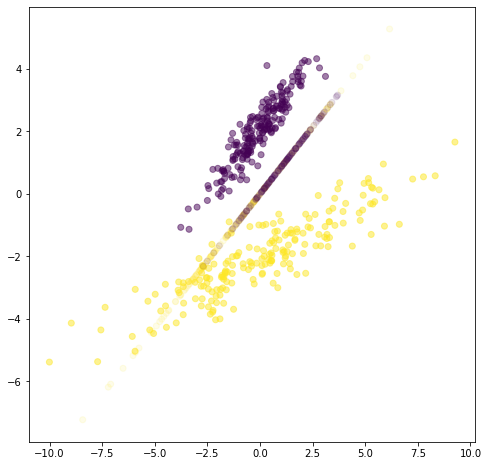
Aunque PCA encuentra componentes que son útiles para representar la variabilidad en los datos, no existe ninguna razón para asumir que dichas componentes deben ser útiles para discriminar entre conjuntos de datos en diferentes clases.
from sklearn.decomposition import PCA
pca = PCA(n_components=1)
pca.fit(X3)
u0 = pca.components_[0]
c = X3.dot(u0)
Xr = np.r_[[i*u0 for i in c]]
plt.figure(figsize=(8,8))
plt.scatter(X3[:,0], X3[:,1], c=Y, alpha=.5, label="original data")
plt.scatter(Xr[:,0], Xr[:,1], c=Y, alpha=.1, label="reconstructed data from largest component")
#plt.legend(loc="center left", bbox_to_anchor=(1.01,.5))
<matplotlib.collections.PathCollection at 0x7f18f2623990>
Xt = pca.transform(X3)[:,0]
plt.figure(figsize=(8,8))
plt.scatter(X3[:,0], X3[:,1], c=Y, alpha=.5, label="$\mathbf{X}$: original data")
plt.scatter(Xt, [0]*len(Xt), c=Y, alpha=.5, label="$\mathbf{X_t}$: reduced data")
<matplotlib.collections.PathCollection at 0x7f18f259bdd0>
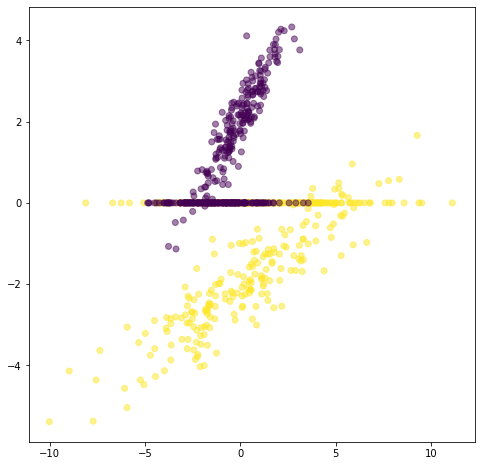
Mientras PCA busca direcciones de proyección que son eficientes para representar los datos, el análisis discriminante busca direcciones que son eficientes para discriminación, es decir que permiten una mejor separación de las clases en el espacio de menor dimensión.
Supongamos que tenemos un problema de clasificación de 2 clases, cada muestra \({\bf{x}}_i\) es \(d\)-dimensional.
Consideremos la proyección de un punto (muestra) con respecto una dirección representada por un vector unitario \({\bf{v}}\)

El escalar \({\bf{v}}^{T}{\bf{x}}_i\) corresponde a la distancia de la proyección de \({\bf{x}}_i\) desde el origen.
¿Cómo medir la separación de las proyecciones de diferentes clases?
Una buena medida de separación entre clases podría ser: \(|\widetilde{\mu}_1 - \widetilde{\mu}_2|\).
de manera similar \(\widetilde{\mu}_2 = {\bf{v}}^{T}\mu_2\)
¿Que tan buena es \(|\widetilde{\mu}_1 - \widetilde{\mu}_2|\) como medida de separación?
¿Entre mayor sea \(|\widetilde{\mu}_1 - \widetilde{\mu}_2|\) mejor será la separación esperada?
np.random.seed(1)
Mean = [1,6]; Cov = [[6,0],[0,0.5]]
Mean2 = [8,2];
x, y = np.random.multivariate_normal(Mean, Cov, 200).T
x2, y2 = np.random.multivariate_normal(Mean2, Cov, 200).T
fig, ax = plt.subplots(figsize=(8,8))
ax.plot(x,y,'o')
ax.plot(x2,y2,'o')
ax.plot(np.array([-8,1]),np.array([6,6]),ls='--',color='black')
ax.plot(np.array([-8,8]),np.array([2,2]),ls='--',color='black')
ax.plot(np.array([1,1]),np.array([6,-8]),ls='--',color='black')
ax.plot(np.array([8,8]),np.array([2,-8]),ls='--',color='black')
ax.set_xlim(-8, 14)
ax.set_ylim(-8, 14)
#ax.set_xticks(np.arange(-6,6,2))
#ax.set_yticks(np.arange(-6,6,2))
ax.set_xlabel('Variable 1')
ax.set_ylabel('Variable 2')
Text(0, 0.5, 'Variable 2')
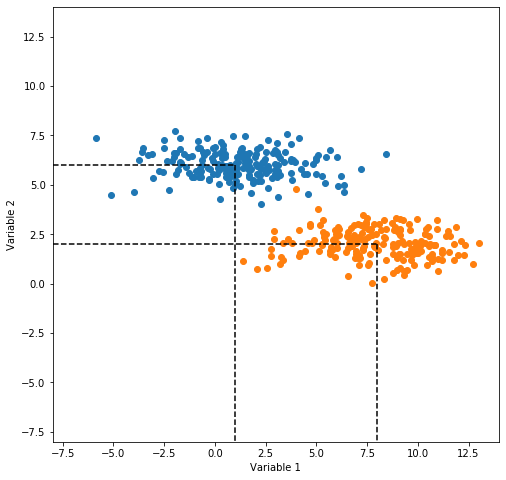
En la figura anterior el eje vertical es una mejor dirección que el eje horizontal para proyectar los datos, teniendo en cuenta la separabilidad entre clases. Sin embargo \(|\hat{\mu}_1 - \hat{\mu}_2|>|\widetilde{\mu}_1 - \widetilde{\mu}_2|\). El problema con la medida anterior es que no considera la varianza de las clases.
Es necesario entonces normalizar \(|\widetilde{\mu}_1 - \widetilde{\mu}_2|\) con respecto a un factor que sea proporcional a la varianza.
Definamos entonces la dispersión \({\bf{S}}\) de un conjunto de muestras como la varianza multiplicada por \(n\), es decir:
La solución proporcionada por el análisis discriminante de Fisher es entonces normalizar la distancia entre las medias por la dispersión.
Sea \({\bf{y}}_i = {\bf{v}}^{T}{\bf{x}}_i\), es decir, \({\bf{y}}_i\)’s son las muestras proyectadas.
La dispersión de las muestras proyectadas de la clase 1 es
La dispersión de las muestras proyectadas de la clase 2 es
Es necesario normalizar con respecto a ambas dispersiones, por lo tanto el análisis discriminante de Fisher proyecta los datos en la dirección \({\bf{v}}\) que maximiza el criterio:
Si encontramos un vector \({\bf{v}}\) que haga a \(J({\bf{v}})\) grande, garantizaremos que las clases están bien separadas.
Lo que se necesita es entonces expresar \(J({\bf{v}})\) en términos de \({\bf{v}}\) y maximizar. Para es necesario definir las matrices de dispersión de las muestras en el espacio original:
Y definamos la matriz de dispersión intra clase como: \({\bf{S}}_W = {\bf{S}}_1 + {\bf{S}}_2\).
Recordando los resultados sobre la media de las muestras proyectadas, se puede llegar a la conclusión que: \(\widetilde{{\bf{S}}}_{1} = {\bf{v}}^{T}{\bf{S}}_1{\bf{v}}\) y de manera similar para la clase 2, \(\widetilde{{\bf{S}}}_{2} = {\bf{v}}^{T}{\bf{S}}_2{\bf{v}}\)
Entonces
Se define la matriz de dispersión entre clases como:
la cual mide la separación entre las medias de dos clases (antes de la proyección). Utilizando nuevamente la definición de las medias proyectadas desarrollada antes es posible obtener:
Por consiguiente el criterio \(J({\bf{v}})\) se puede expresar como:
Para minimizar derivamos \(J({\bf{v}})\) con respecto a \({\bf{v}}\) e igualamos a cero. Después de algunas operaciones matriciales se llega a:
Que corresponde nuevamente a un problema de cálculo de valores propios pero está vez de la matriz \({\bf{S}}_W^{-1} {\bf{S}}_B\). Es posible también encontrar que para un caso bi-clase, la proyección que maximiza el criterio de Fisher corresponde al vector \({\bf{v}} = {\bf{S}}_W^{-1} (\mu_1 - \mu_2)\).
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from numpy.linalg import inv
np.random.seed(1)
X = np.dot(np.random.random(size=(2, 2)), np.random.normal(size=(2, 200))*4).T
X2 = np.dot(np.random.random(size=(2, 2)), np.random.normal(size=(2, 200))).T + np.array([0,4])
X3 = np.r_[X,X2]
Y = np.r_[np.ones(200),np.zeros(200)]
# center data on 0,0
X3=X3-np.mean(X3, axis=0)
clf = LinearDiscriminantAnalysis(solver='eigen')
X_t = clf.fit_transform(X3,Y)
u0 = np.dot(np.dot(inv(np.dot(X3.T, X3)),X3.T),X_t)
c = X3.dot(u0)
Xr = np.r_[[i*u0 for i in c]]
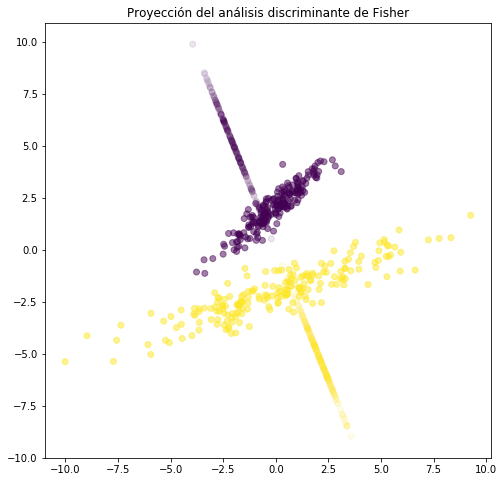
plt.figure(figsize=(8,8))
plt.scatter(X3[:,0], X3[:,1], c=Y, alpha=.5, label="original data")
plt.scatter(Xr[:,0,0], Xr[:,1,0], c=Y, alpha=.1, label="reconstructed data from largest component")
plt.title('Proyección del análisis discriminante de Fisher')
#plt.legend(loc="center left", bbox_to_anchor=(1.01,.5))
Text(0.5, 1.0, 'Proyección del análisis discriminante de Fisher')
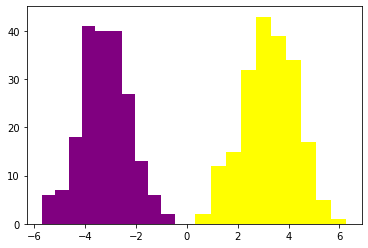
plt.hist(c[Y==1],color='purple')
plt.hist(c[Y==0],color='yellow')
(array([ 2., 12., 15., 32., 43., 39., 34., 17., 5., 1.]),
array([0.33583526, 0.92962845, 1.52342165, 2.11721485, 2.71100804,
3.30480124, 3.89859443, 4.49238763, 5.08618083, 5.67997402,
6.27376722]),
<a list of 10 Patch objects>)
El análisis discriminante de Fisher se puede generalizar para múltiples clases, en cuyo caso el criterio a optimizar es:
donde \({\bf{V}}\) es llamada la matriz de proyección.
 Image taken from [1].
Image taken from [1].
Otros ejemplos:¶
Veamos un ejemplo usando la base de datos iris:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target
import matplotlib.pyplot as plt
Proyecciones usando PCA¶
from sklearn.decomposition import PCA
pca = PCA(1) # only keep one dimension!
X_E = pca.fit_transform(X)
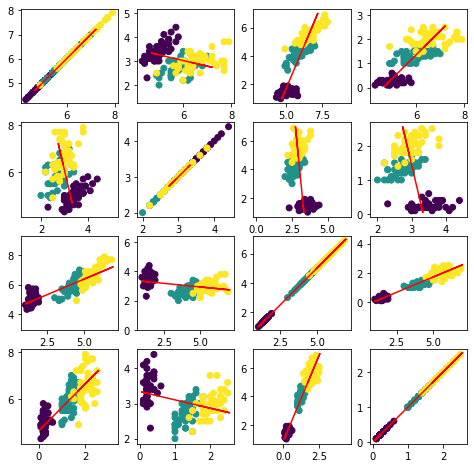
En la figura siguiente, las líneas rojas representan las direcciones de mayor varianza de acuerdo con el criterio de PCA, para las diferentes combinaciones de variables de entrada.
X_reconstructed = pca.inverse_transform(X_E)
plt.figure(figsize=(8,8))
for i in np.arange(4):
for j in np.arange(4):
plt.subplot(4, 4, i * 4 + j + 1)
plt.scatter(X[:,i], X[:,j],c=y)
plt.plot(X_reconstructed[:,i], X_reconstructed[:,j],c='r')
plt.axis('equal')
plt.figure(figsize=(8,8))
<Figure size 576x576 with 0 Axes>
<Figure size 576x576 with 0 Axes>
La figura siguiente muestra los datos proyectados en las direcciones de mayor varianza.
plt.figure(figsize=(8,8))
for i in np.arange(4):
for j in np.arange(4):
plt.subplot(4, 4, i * 4 + j + 1)
plt.scatter(X_reconstructed[:,i], X_reconstructed[:,j],c=y)
plt.axis('equal')
plt.figure(figsize=(8,8))
<Figure size 576x576 with 0 Axes>
<Figure size 576x576 with 0 Axes>
Proyecciones usando LDA¶
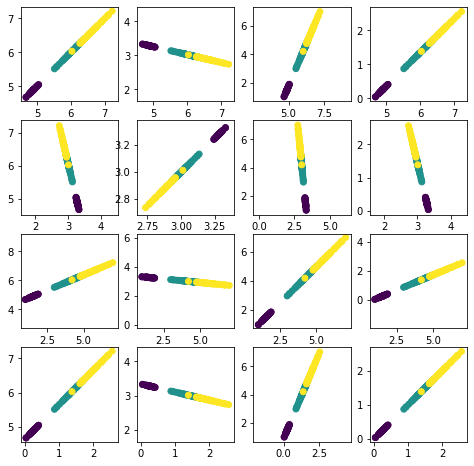
En las figuras siguientes se muestran el espacio transformado por LDA y las proyecciones de mayor discriminación (líneas rojas) de acuerdo con el criterio de LDA, para las diferentes combinaciones de variables de entrada.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from numpy.linalg import inv
clf = LinearDiscriminantAnalysis(solver='eigen')
X_t = clf.fit_transform(X,y)
u = np.dot(np.dot(inv(np.dot(X.T, X)),X.T),X_t)
X_reconstructed = np.dot(X_t[:,0].reshape(X_t.shape[0],1),u[:,0].T.reshape(1,4))
La figura siguiente muestra los datos proyectados en las direcciones de mayor discriminación.
plt.figure(figsize=(8,8))
for i in range(4):
for j in range(4):
plt.subplot(4, 4, i * 4 + j + 1)
plt.scatter(X_reconstructed[:,i], X_reconstructed[:,j],c=y)
plt.axis('equal')
plt.figure(figsize=(8,8))
<Figure size 576x576 with 0 Axes>

<Figure size 576x576 with 0 Axes>