
Introdución para los laboratorios de Machine Learning
Contents
Recuerda que una vez abierto, Da clic en “Copiar en Drive”, de lo contrario no podras alamancenar tu progreso
# Siempre Ejecuta esta linea de codigos
# esta configura librerias y ciertas funciones
# necesarias para esta sesión
!wget https://raw.githubusercontent.com/jdariasl/ML_2020/master/Labs/commons/utils/general.py -O general.py
from general import configure_intro
configure_intro()
from intro import *
Introdución para los laboratorios de Machine Learning¶
Este sección explica los laboratorios que realizarán durante el curso.
Los laboratorios están en Python 3.7
Son escritos usando notebooks
Estan adaptados para ser ejecutados en la herramienta Google Colab.
En este notebook veremos la siguiente información que sera nuestra base para todas nuestras sesiones.
Introducción a Google Colab como usarlo para el desarrollo de las practicas
Conceptos rapidos de Python
Básicos y más importantes
Profundización (Lectura y práctica)
Manejo de vectores y matrices en NumPy
Básicos y más importantes
Profundización (Lectura y práctica)
Manejo de estructuras de datos en pandas. Graficos en matplolib
Básicos y más importantes
Profundización (Lectura y práctica)
Estructuras de los laboratorios
En cada una de las secciones pueden encontrar diferentes ejercicios para ir practicando y afianzado los conceptos presentados.
Google Colab y Jupyter Notebooks¶
Un Jupyter notebook es un proyecto open source que permite ejecutar interactivamente varios lenjuages de programación. Su nombre es un referencia a los lenguajes que fueron principales en el inicio el proyecto: JUlia, PYThon y R. Pero en la actulidad se han expandido a muchos otras más. Este proyecto también se conocio antes bajo el nombre de IPython Notebooks. Los notebooks, en su formato “crudo” son un archivo JSON que es renderizado para permitir combinar tanto codigo, texto (Usando Markdown), lenguaje matemático y graficas.
Los notebooks pueden ser ejecutados en diferentes entornos. Estos entornos pueden ser locales (requieren instalación y configuración) o en la nube por medio de un navegador moderno (no requiere ninguna configuración).
Distribuición de Anaconda. (Recomendado para Windows y macOs)
Administrador de paquetes pip. (Recomendado para Linux) Tutorial
Contenedor en docker
Como se ha mencionado, este notebook y el resto de nuestros sesiones están adaptados para usar Google Colab, pero con un muy pequeño esfuerzo también pueden ser adaptados para ser ejecutados en cualquier entorno mencionado. Esto ultimo no es recomendado y no es objetivo del curso, y no se podrán revisar laboratorios que no sigan las instrucciones detalladas en la ultima sección de este documento.
En la industria, los jupyter notebooks son un herramienta altamente adoptada y se considera un “estandar” para el desarrollo, documentación y comunicación de resultados de investigación en trabajos de ciencia de datos.
Sin embargo también ha logrado una buena pouplaridad en otros entornos. inlcusive, se ha discuito que pueden ser una buena alternativa para susbtituir el formato estandar del paper cientifico.
De la misma manera los jupyter notebook son la base para productos comerciales de los principales proveedores de computación en la nube como lo son:
AI Platform De Google Computing Platform. O VertexAI
Amazon SageMaker de Amazon Web Services
Azure Notebooks de Microsoft Azure
Y otros servicios usados en entornos de Big Data como son Databricks, Cloudera y Apache Zepelin.
Sin embargo es totalmente vital, aclarar que los notebooks son un entorno para exploración interactiva y presentar resultados que sean reproducibles. No es recomendado su uso para tareas de software engineering “más puras” (codigo de una aplicación,API, codigo de un sistema productivo, etc).
Cada dia cobra mas fuerza la siguiente idea: los notebooks son usados en las primeras etapas de desarollo de una aplicación de ML. Pero cuando el modelo cada vez esta más cerca a un entorno “productivo”, el codigo de un notebook debe ser refactorizado a un codigo que sea mas sencillo de mantener y administrar (En este video se hace una discusión interesante y otras críticas).
En las últimas sesiones de nuestro laboratorio, realizaremos una práctica donde ahondaremos un poco más en este tema.
Manejo de Google Colab¶
Colaboratory, o Colab, permite escribir y ejecutar código de Python en un navegador, con las siguentes ventajas:
Sin configuración requerida (Python, Jupyter)
Acceso gratuito a GPU
Facilidad para compartir y desarrollar los notebooks de manera interactiva
Mira este video introductorio sobre Colab, para entender como Colab nos ayuda agilizar algunas tareas. El icono de launch en la parte superior derecha permite lanzar el notebook directamente Colab.
En Colab, existen dos tipos de celdas:
Las celdas de texto: estan escrita con Markdown, un lenguaje de etiquetado más legible para la decoración de texto, se puede hacer desde encabezados, usar LaTeX, símbolos matemáticos, listas enumeradas, entre otros.
Las celdas de código: son ejecutables, es decir, se pueden correr individualmente.
Recuerda que una vez abierto, Debes dar clic en “Copiar en Drive”. De lo contrario no podras alamancenar tu progreso y ni compartirlo con tu profesor.
Como se menciono, cada celda de codigo se ejecuta por separado. Esto implica que la ejecución se realiza de arriba hacia abajo en orden. Es así como evitamos problemas de importación de librerías o variables sin definir.
Por ejemplo, esta es una celda de código con una secuencia de comandos Python corta que calcula un valor, lo almacena en una variable y devuelve el resultado:
(A fin de ejecutar el código en la celda anterior, haz clic en él para seleccionarlo y, luego, presiona el botón de reproducción ubicado a la izquierda del código o usa la combinación de teclas “Command/Ctrl + Intro”. )
seconds_in_a_day = 24 * 60 * 60
seconds_in_a_day
Para editar el código, solo haz clic en la celda y comienza a editar. Las variables que defines en una celda pueden usarse en otras:
seconds_in_a_week = 7 * seconds_in_a_day
seconds_in_a_week
Ahora es tu turno Haz click en la opción “+ Texto” (en la parte de arriba o al final de la celda, tambien te debe aparecer si dirijes el puntero en la parte inferior de la celda). Añade una celda de texto y prueba escribir algo.
Luego, añade una celda de código en la opción ” + Codigo” (en la parte de arriba o al final de la celda, tambien te debe aparecer si dirijes el puntero en la parte inferior de la celda) y escribe las siguientes lineas y ejecutalas.
zero_to_nine = range(0,10)
for n in zero_to_nine:
print(n)
¿cual es la salida?
Tambien es de utilidad conocer los shorcuts o accesos rapidos de colab, explora que combinaciones de teclas te pueden servir para agilizar el trabajo en Colab.
Conceptos de Python¶
En esta sección se hace una presentación de conceptos utiles de Python, si bien para el desarrollo del curso no es necesario y no se busca que las practicas esten enfocadas a desarrollar habilidades especificas de Python, si es de utilidad tener claras algunas capacidades de Python.
Durante nuestra sesión
Básicos¶
Aca solo veremos conceptos que van ser muy comunes en nuestro laboratorio. Se recomienda leer y praticas la siguiente subsección.
# Tuplas
tup = (1, "hola", 3)
print (tup[0])
#tup[1] = 2 #Esto es un error
# Listas
lista = [2, 3, 2.5, "Hola"]
print (lista[2])
lista[2] = "nuevo"
print (lista[2])
# Diccionarios
dic = {"clave": "valor", "1": 324, "2": "Hola"}
print (dic["clave"])
## Estrucutra if else
age=17
if age>18:
print("you can enter to concert" )
elif age==18:
print("You can enter after listen Pink Floyd")
else:
print("You cannot enter, instead you can listen Black pink / BTS" )
print("move on")
dates = [1982,1980,1973]
N=len(dates)
# iterar en el indice
for i in range(N):
print(dates[i])
# iterar en los elementos
for i in dates:
print(i)
# usar enumerate
for n,i in enumerate (dates):
print(n, i)
# iterar en dos listas de igual tamaño
a = [1, 2, 3]
b = ["one", "two", "three"]
for num, letra in zip(a,b):
print(num,letra)
Profundización¶
#Conjuntos
conjunto = {1, 3, "hola"}
print(conjunto)
## Ciclos Whiles
dates = [1982,1980,1973,2000]
i=0;
year=0
while(year!=1973):
year=dates[i]
i=i+1
print(year)
print("it took ", i ,"repetitions to get out of loop")
# funciones
def is_a_sum_with_bonus(a,b):
a = a +1
resultado = a + b
return (resultado)
is_a_sum_with_bonus (10, 5)
is_a_sum_with_bonus (0, 10)
# manejo de strings
string = "welcome " + "to Python"
print (string)
# multiplicacion de cadenas
string = "is Python!" * 2
print (string)
# uso con otros tipos de datos
string = "This is test number " + str(15)
print (string)
# obtener subcadenas
string = "first second third"
print(string[:2])
print(string[2:])
print(string[3:5])
print(string[-1])
# cadenas a numeros
string="10"
string2="20"
print(string+string2)
print(int(string)+int(string2))
# contar caracteres
string="welcome to course of ML"
print(min(string))
print(max(string))
print(len(string))
Manejo vectores y matrices en NumPy¶
NumPy es un paquete que proporciona herramientas y técnicas para manipular estructuras de datos con matrices, es mucho mejor que las listas de Python, tiene acceso y escritura más rápida. Posee una amplia colección de herramientas y técnicas que se pueden utilizar para resolver problemas mátematicos, además de que contiene todas las funciones para trabajar con matrices.
A continuación encontrá algunas funciones muy útiles para los laboratorios, tales como:
Creación de matrices
Suma y resta de vectores
Producto de dos vectores
Producto de dos matrices
Multiplicación matricial
Indexación de matrices
Y en la subsección Siguiente se da algunos ejemplos para profundizar en el manejo de numpy.
Básicos¶
El paquete NumPy introdujo los arrays N-dimensionales, acontinuación se mostrará las rutinas más utilizadas en los laboratorios. (Más rutinas aquí)
#Creacion de array de ceros y unos
zeros=np.zeros(10)
print("Array de 10 ceros:", zeros)
ones=np.ones(10)
print("Array de 10 unos:", ones)
array1 = np.arange(5) # Array de 5 enteros contando el 0
print("Array de 5 enteros: ",array1)
line = np.linspace(0.0, 1.0, 5) #start, stop, num de puntos
print("Array organizados unif.: ",line)
v1 = np.array([8,6,-5,76,9.7]) #Array de una lista
print("Array de una lista: ",v1)
## Ejercicio Crear array de ceros con dimension 3x2**
### HINT: ¿como es el parametro a np.zeros?
# Inicializar un vector manualmente de 1D
#Array de una lista
v1 = np.array([3,-1,2])
v2= np.array([2,-1,3])
print("v1: ",v1)
print("v2: ",v2)
# Suma y resta de vectores
#(para la resta usamos -)
suma1 = v1 + v2
print(suma1)
# producto elemento a elemento
prod1 = v1*v2
print ("Producto elemeto a elemento",prod1)
#Producto matricial
prod1 = np.dot(v1,v2)
print ("Producto matricial",prod1)
prod2 = v1 @ v2
print("Producto matricial",prod2)
Escribe el codigo de Python usando numpy, para realizar la siguiente operacion, siendo \(\odot\) la representación de la multiplicación elemento a elmento, y \(\cdot\) el producto matricial.
\(r = (v_{1}\odot v_{2}) + v_{1} - v_{2} + (v1 \cdot v2) \)
Siendo v1 y v2 los vectores v1 y v2 ejecutadas en la celda anterior. Finalmente imprime el resultado r.
En este ejercicio tambien vas observar en funcionamiento un concepto de numpy llamado Broadcasting.
## Ejercicio: Escribe aca la operación
### El resultado debe ser [20, 14, 18]
r =
print (r)
# Indexar una matriz manualmente 2x3
# la entrada en una lista de lista.
# cada lista es un renglon de la matriz
# cada renglon debe tener las mismas columnas
# (el mismo tamaño de lista)
m1 = np.array([[1,2,3],[0.5,0.3,2.1]])
print (m1)
¿Cuántas filas y columnas tiene la variable m1?
print("Shape m1", )
m2 = np.array([[1,2],[2,1],[3,1]]) # [3x2]
print ("dimensiones de m2",np.shape(m2))
print(m2)
#Producto de dos matrices
print ("Productor de dos matrices \n",np.dot(m1,m2))
print("Producto de dos matrices @\n",m1@m2)
#Producto elemento a elemento
m3 = np.array([[1,2],[2,1]]) # [3x2]
print ("ls dimensiones es de m3", np.shape(m3))
print(m3*m3)
¿Por qué el siguiente código produce error?
print (m1*m2)
Se debe organizar las dimensiones de la matriz para hacer la multiplicación elemento a elemento correctamente.
¿Cómo se puede solucionar?
# usando la transpuesta!
m1_new = m1.T
print("New shape m1", m1_new.shape)
print(m1_new*m2)
# pero también podria hacer re-shape?
m1_new2 = m1.reshape((3,2))
print("New shape m1", m1_new2.shape)
print(m1_new2*m2)
m1_new2 = m1.reshape((3,-1))
print("New shape m1", m1_new2.shape)
print(m1_new2*m2)
¿Hay alguna diferencia con la matriz m1 después de hacer el reshape, los resultados son diferentes?
Reshape: Asigna una nueva forma a la matriz ya sea un entero para una dimensión o una tupla para N-Dimensiones
a = np.arange(6).reshape((3, 2))
a
b = np.arange(6).reshape((3,1,2))
b
b = b.reshape((6))
b
¡Cuidado con la asignación de variables! Python usa variables referenciadas. Si se requiere hacer una copia se debe usar el método “.copy”.
# si se usa = se crea una referencia
print("m1 antes de hacer la referencia \n", m1)
m4 = m1
m4[0,1] = 9
print ("M1 se modifica aunque no se 'hizo' ninguna operacion a esta variable ""m1\n",m1)
print ("Ahora con el metodo copy")
print("m1 antes de hacer el copy \n", m1)
m5 = np.copy(m1)
m5[1,1] = 9
print ("m5 es m1 con el valor modificado \n",m5)
print ("Pero m1 esta vez no es modificado")
print ("m1 \n",m1)
Para hacer una indexación en matrices se accede con los corchetes y siempre se define así: [filas,columnas]. Observa que la separación se realiza con una coma ( , )
x = matrix[filas, columnas]
Si deseo escoger entre la fila x hasta y debe ser separado por dos puntos :, de la siguiente forma:
x = matrix[x:y,]
De la misma forma aplica para las columnas, si quiero la primera columna:
x = matrix[0:2,0:1]
Acceder a los últimas posiciones:
x = matrix[0:-1,0:-1]
print("Original m2")
print(m2)
print("----")
new_m2 = m2[0:2,]
print("Nuevo m2, dos primeras filas")
print(new_m2)
new_m2 = m2[0:2,0:1]
print("Nuevo m2, dos primeras filas y primera columna")
print(new_m2)
m4 = np.arange(5,25).reshape((10,2))
m4
## Ejercicio: Obtener las últimas dos filas del anterior vector
## Hint: debe retonar [[21, 22], [23, 24]]
last_m2 = m4[]
last_m2
Concatenar vectores y matrices
a = np.array([[1,5,9], [2,6,10]])
b = np.array([[3,7,11], [4,8,12]])
print("a:\n ", a, "\n b: \n", b)
np.concatenate((a,b), axis=0)
np.concatenate((a, b), axis=1)
np.vstack((a, b))
## Algunas veces es util, obtener una lista
## de los elementos que están la matriz
## si bien el reshape puede ser usado
## np.ravel() puede ser usado para ese objetivo
a = np.array([[1,1, 1], [2,2,2], [3,3,3]])
print("antes del ravel \n ", a, "\n usando ravel \n ", np.ravel(a))
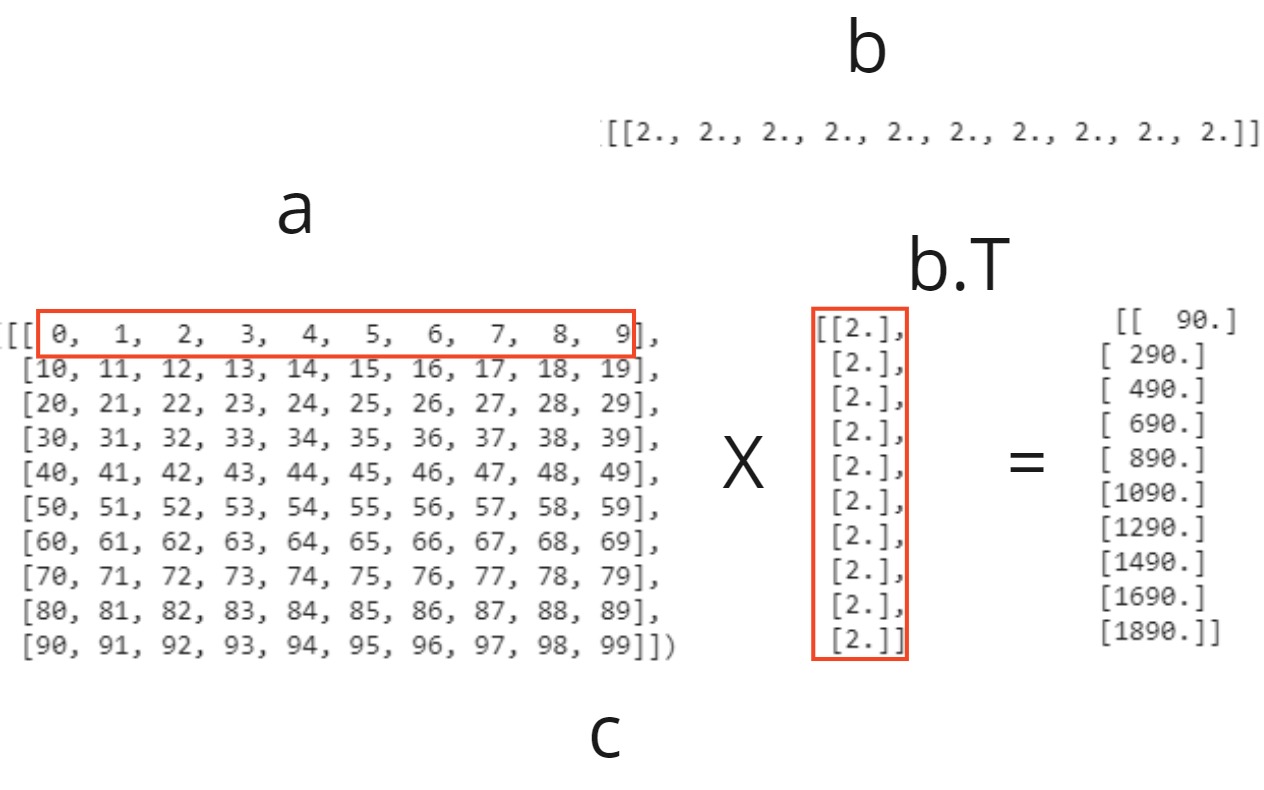
Recordar que el uso de numpy es preferido para la implementación, de los algoritmos, ya que al usar la libreria, los codigos son mas efecientes y se logran los beneficios de la vectorización, por ejemplo, al realizar la siguiente operación, es posible realizarla con ciclos for. pero al usar la representación matricial y las librerias de numpy tenemos algunos beneficios.
\(m = a \cdot b \)
print("shape de a", matriz_a_for.shape)
print("shape de b", matriz_b_for.shape)
Usando esta imagen entendemos, un poco mas la operación
# implementacion con numpy
import time
results = []
for n in range(10):
s = time.time()
m = np.dot(matriz_a_for, matriz_b_for.T)
results.append(time.time() - s)
print("time en ms", np.mean(results)*1000, "\n results \n ",m)
## Implementacion la operacion mediante ciclos for
m = np.zeros(shape = (10,1))
results = []
for n in range(10):
s = time.time()
for i in range(m.shape[0]):
aa = np.sum(matriz_a_for[i, :]*matriz_b_for)
m[i,0] = aa
results.append(time.time() - s)
print("time en ms", np.mean(results)*1000, "\n results \n ",m)
Con ciclos for tenemos una implementación que es casi 200 % más lenta que la implementación “vectorizada”.
Profundización en numpy¶
## Calculo del promedio
a = np.array(range(5))
print("vector", a, "promedio", np.mean(a))
print("vector", a, "promedio con axis = 1, es equivalante al anterior", np.mean(a, axis = 0))
## el parametro axis es mas util en una matriz
a = np.array(range(6)).reshape((3,2))
print("vector \n", a, "\n promedio con axis = 0\n", np.mean(a, axis = 0))
print("vector \n ", a, "\n promedio con axis = 1\n " , np.mean(a, axis = 1))
## equivalente con min, max y sum
print ("extraer la suma: ", a.sum(), "o de esta manera", np.sum(a))
print ("igualmente el parametro axis es util, con axis = 0 \n", np.sum(a, axis = 0),
"\n y axis = 1 \n ", np.sum(a, axis = 1))
# generar un valores aleatorio
x = np.random.choice(2,size = 10)
print(x)
x = np.random.choice(10,size = 10)
print(x)
## extrar los valores unicos y contar la frequencia de
## de estos mismos
uniq = np.unique(x)
print("devuelve los valores unicos", uniq)
uniq = np.unique(x, return_counts=True)
print("y con esta opciones devuelve una tupla \n ", uniq,
"\nel primer elemento de la tupla son los valores",
uniq[0],
"\n el segundo elemento el contador \n",
uniq[1])
## Ejercicio: explorar la funcion de estos
## y que parametros pueden recibir
## metodos
#ones :
np.ones()
#diag:
np.diag()
#linalg.inv #Inversa de matriz:
np.linalg.inv()
#linalg.svd #Descomposición en valores singulares:
np.linalg.svd()
#logical_and #Elemento a elmento:
np.logical_and()
#logical_or #Elemento a elelemto:
np.logical_or()
Manejo de estructuras de datos en Pandas. Graficos en matplotlib¶
Básicos¶
# en la configuracion inical se hace import pandas as pd
# lectura de un csv
datos = pd.read_csv("bank.csv", sep = ";")
# esto crea un pandas dataframe
# Pandas es una libreria muy popular para el manejo de datos
# y se integra con los notebooks de manera muy sencilla
datos.head()
# sample para explorar los datos de manera rapida
datos.sample()
# y se puede interpretar como una matriz de numpy:
print ("puedes ver los datos de shape ", datos.shape)
# pero para acceder a ellos es más similar a una tabla
print("en forma de renglon 10 todas las columnas, pero retorna una serie")
datos.loc[9, :]
print("en forma de renglon 10 todas las columnas, pero retorna una df una tabla")
datos.loc[[9], :]
# puedes tambien filtrar columnas y mostrar multiples df con display
print("primer filtro")
display(datos.loc[[9], ['age', 'job', 'marital']])
print("segundo filtro")
# mostrar los rengloes de 10 al 15
display(datos.loc[range(9,15), ['age', 'job', 'marital']])
# sin embargo esta soporta mas tipos de datos, pero se pueden seguir haciendo operaciones
# similares con las columnas numericas
# y puedes referenciar las columnas
datos['day'] + datos['pdays']
Vamos aprovechar tambien los df, para hacer tablas para nuestros experimentos. Podemos ir agregando resultados a la tabla
# creacion de una tabla
# con resultados
errores = [0.1, 0.2,0.3, 0.01]
parametros = [1,2,3,5]
# se crea df vacio
results = pd.DataFrame()
i = 0
for e,p in zip (errores, parametros):
results.loc[i, "parametro"] = p
results.loc[i, "error"] = e
results.loc[i, "tipo"] = "entrenamiento"
i+=1
for e,p in zip (errores, parametros):
results.loc[i, "parametro"] = p
results.loc[i, "error"] = e
results.loc[i, "tipo"] = "validacion"
i+=1
results
Manejo de gráficas en matplotlib y pandas
Ahora utilizaremos la librería matplotlib para hacer algunos ejemplos de gráficas básicas:
Observemos que la variable x solo se carga en la primera celda de código. En adelante se puede usar sin necesidad de ser cargada de nuevo. En la gráfica de \(y=x^3\) incluimos el título de la gráfica y los label para los ejes de la misma.
#x = np.array([-2,-1,0,1,2])
x = np.linspace(-10,10,100)
#Función y = ax + b
y = 0.5*x
plt.plot(x,y)
plt.ylim(0,10)
plt.xlim(0,10)
plt.ylabel('y = x')
plt.xlabel('x')
plt.title(u"Gráfica de una función lineal\n")
plt.show()
y = x**2
plt.plot(x,y, c='green')
#plt.xlim(-150,150)
plt.show()
y = x**3
plt.plot(y)
plt.ylabel(r'$y = x^3$')
plt.xlabel(u'x - 100 números entre -10 y 10')
plt.title(u'Ejemplos de introducción para el curso de Simulación de Sistemas - UdeA\n')
plt.show()
Generando gráfica punteada
y = np.sin(x)
plt.plot(y, 'b-')
plt.ylabel('y = seno(x)')
plt.xlabel(u'x - 100 números entre -10 y 10')
plt.title(r'$s(t) = \mathcal{A}\sin(2 \omega t)$', fontsize=16, color='r')
plt.show()
Dos gráficas en el mismo plano
y2 = x
y = np.sin(x)
y1 = np.cos(x)
plt.plot(y, 'r--', y1, 'b-')
plt.ylabel('y = seno(x)')
plt.xlabel(u'x - 100 números entre -10 y 10')
plt.title(u'Ejemplos de introducción para el curso de Simulación de Sistemas - UdeA\n')
plt.show()
Agregando el legend al gráfico
y = np.sin(x)
y1 = np.cos(x)
plt.plot(y, 'r-', label='Seno')
plt.plot(y1, 'b-', label='Coseno')
plt.ylabel('y = seno(x)')
plt.xlabel(u'x - 100 números entre -10 y 10')
plt.title(u'Ejemplos de introducción para el curso de Simulación de Sistemas - UdeA\n')
plt.legend()
plt.show()
De igual manera, si tenemos un pandas dataframe, se puede simplificar nuestros codigos, y podemos hacer plots con menos lineas de codigo.
datos.plot()
results.plot.bar(x ='tipo', y='error')
results.groupby(['tipo'])['error'].mean().plot.bar()
Profundización¶
Graficas de barras
values = np.array([1, 10, 100])
ind = np.arange(3)
plt.figure(1, figsize=(9, 3))
plt.subplot(131)
plt.bar(ind+1, values*np.random.rand(3))
plt.subplot(132)
plt.bar(ind+1, np.flipud(values))
plt.subplot(133)
plt.bar(ind+1, values)
plt.suptitle(u'Ejemplos - Simulación de Sistemas y Lab.')
plt.show()
Gráficos para problemas de clasificación en Machine learning. Scatter plots
#Creamos los datos artificiales
mu1, sigma1 = 1.5, 0.1
mu2, sigma2 = 1, 0.1
N = 100
x1 = mu1 + sigma1 * np.random.randn(N)
x1line = np.linspace(0,2,N)
x2 = mu2 + sigma2 * np.random.randn(N)
x2line = np.linspace(3,5,N)
#Decision boundary
b = -2
m = 3.5
v = np.linspace(0,100,100)
t = v*m + b
plt.scatter(x1, x1line, c='b')
plt.scatter(x2, x2line, c='r')
plt.plot(v, t, 'c-')
plt.ylim(-0.5, 6, 1)
plt.xlim(0.5, 1.8, 0.2)
plt.show()
También representar gráficas para visualizar relaciones matemáticas útiles
\(P(x; \mu, \sigma) = \frac{1}{\sqrt{2\pi}\sigma }exp-\frac{1}{2}\frac{(x-\mu)^2}{\sigma^2}\)
mu, sigma = 0, 2
#Generamos un conjunto de valores x
x = np.linspace(-3,3,100)
#los llevamos a la función de densidad de probabilidad normal
p = ( 1/(np.sqrt(2*np.pi)*sigma) ) * np.exp( (-1/2) * ( ((x - mu) ** 2) / (sigma ** 2) ) )
plt.plot(x, p, 'r--')
plt.show()
p = np.random.randn(1000)
plt.hist(p, color = 'b')
plt.show()
Ejercicio!
Explora un poco más la librería de pandas
Explora esta librería de visualizacion que se integra con pandas
Estructura de los laboratorios¶
En los laboratorios van encontrar diferentes clases de ejercicios, estos se pueden resumir en los siguientes puntos
Contextualización del problema y entedimiento de los datos
Se busca que tenga un contexto del problema que se está abordando, de modo que les ayude a resolver los ejercicios. Es de suma importancia entender de fondo si es un problema de clasificación o regresión. En cuanto a los datos con los que trabajaremos, identificar el número de clases, muestras y carácteristicas. Esto les ayudará para entender los resultados una vez completen los algoritmos y hacer gráficas, responder preguntas abiertas entre otros.
Completar el código
Hacer la implemetación del algoritmo del modelo. Son modelos que se explicaron en la teoría vista en clase, una vez comprenda su funcionamiento se completa ya sea el algoritmo o la implementación correcta de las librerías usando los recursos que ya tiene el laboratorio.
Entrenamiento y resultados
En este punto debe hacer uso de las funciones escritas en el punto anterior para realizar el proceso de modelamiento y simulación de los datos de cargados en el punto 1. En escencia tambien es un ejercicio de completar código, pero usando funciones previas y/o completar código para generar una tabla de resultados y derivar conclusiones de estos mismos.
Los ejercicios para completar parte del código, son similares al siguiente:
#La celda comenzara con este aviso:
## Ejercicio de Codigo ##
# Se te requerira completar una función cuyas especificaciones
# y desables se explicán, en la documentacion de la función
# puedes agregar celdas de codigo para y verificando y testeando lo que necesites
# cuando estes seguro comienza a escribir tu codigo
# dentro de la función
# NO MODIFIQUES el nombre de la funcion
def mult_matrices (matriz_a, matriz_b):
"""Esta funcion debera devolver la multiplicacion de matrices entre las dos matrices entrantes
matriz_a, matriz_b: matrices en numpy
retorna: debe retornar el resultado de multiplicar las dos entradas
"""
# Aqui comienza a completar tu codigo
#res = np.dot(matriz_a, matriz_b, axis = 1)
#res = matriz_a + matriz_b
res = np.dot(matriz_a, matriz_b)
# debes retornar siempre lo requerido
return(res)
# seguido de la celda siempre encontraras el codigo para testear si tu implementacion fue correcta
## Es muy importante que esta celda de codigo NO la modifiques
GRADER_INTRO_LAB.run_test("ejercicio1", mult_matrices)
## tambien vas a encontrar ejercicios similares a este
# donde tu funcion debe ejecutar el codigo del modelo
## y retornar el modelo entrenado
## Ejercicio de Codigo ##
def train_model(Xtrain, ytrain, param):
""" esta función debe entrenar un modelo de regression pero solo inicializando
aleatorimente
train_data: a matriz numpy con las muestras de entrenamiento
train_labels: a matriz numpy con labels de entrenamiento
param: este parametro es un dummy no debes hacer nada!
retorna: la matriz W inicializada, y el error de entrenamiento
"""
W = np.random.rand((Xtrain.shape[1])) # np.ones((Xtrain.shape[1])) # np.ones((Xtrain.shape[1]))
error = np.mean(np.dot(Xtrain, W) - ytrain)
return (W,error)
#return (None)
## la funcion que prueba tu implementacion
GRADER_INTRO_LAB.run_test("ejercicio2", train_model)
# y con las funciones debes usarla para completar los experimentos y llenar el dataframe
# debes variar el parametro de 0 a 5
## Ejercicio de Codigo ##
def experimentar (Xtest, ytest, params):
"""Esta función debe realizar los experimentos, de manera programatica.}
Debe devolver un datarame con los errrores por cada parametro.
Xtest: matriz numpy con los valores del conjunto para test
ytest: los valores de etiqueta reales
retorna: un dataframe con dos columnas: el valor del parametro y el valor del error
"""
#params = range(5)
resultados = pd.DataFrame()
for i, param in enumerate (params):
W, err = train_model(Xtest, ytest, param)
resultados.loc[i,'param'] = param
resultados.loc[i,'err'] = err
return (resultados)
## la funcion que prueba tu implementacion
GRADER_INTRO_LAB.run_test("ejercicio3", experimentar)
De igual manera, en cada notebook van a encontrar preguntas abiertas, Que deberán ser respondidas con:
los resultados del laboratorio,
información vista en clase
pequeña investigación relacionada con la tematica de la sesión.
#@title Pregunta Abierta
#@markdown ¿es necesario siempre una inicialización aleatoria de las variables?
respuesta1_1 = "" #@param {type:"string"}
Recuerda seguir el código del honor y responder concientemente:
son un es espacio de aprendizaje
sirven para afianzar tus conocimientos
sirve para validar como interpretas lo que haces
sirven para practicar la síntesis de tu entedimiento
son revisadas (hay algoritmos que me ayudan a detectar respuestas similares… ¡incluso de semestres pasados!)
# en las ultimas partes del laboratorio vas encontrar esta linea de codigo
# sirve para verificar que todo esta completo
GRADER_INTRO_LAB.check_tests()
NOTA de test automaticos y preguntas abiertas
Los test miden que tu código más que simplemente se ejecute se esté comportando como se debe.
Sin embargo debido a que podemos relizar varias soluciones que pueden no estar cubiertas en los tests (adicionado que estos test fueron escritos por un profersor que es humano) se hadn detectado algunos casos que el test no evalúa de manera totalmente correcta la función que se está pidiendo. Esto puede influenciar respuestas no validadas en las preguntas abiertas
En estos casos la calificación del código es correcta y se ganan los puntos. Pero en la pregunta abierta no aplicaría lo mismo. La idea de las preguntas abiertas es saber que estamos entendiendo qué está haciendo el código no simplemente que se ejecute bien o que pase el test. si hay un error que no se detecta antes de iniciar nuestra sesión de laboratorio, si el test era exitoso los puntos son válidos
Ante la duda, de observar que un test este pasando pero los resultados no coinciden con lo que esperamos, preguntar.
Finalmente al final de cada notebook, encontrarán un formulario que debe ser diligenciado con la información correspondiente.
USAR LAS CEDULAS
#@title Integrantes
codigo_integrante_1 ='' #@param {type:"string"}
codigo_integrante_2 = '' #@param {type:"string"}
¿como se considera un laboratorio entregado?
Debes descargar el archivo .ipynb
Entrar al formulario, subir el archivo y enviar el formulario
Se tomara en cuenta el ultimo envio del formulario. (esto tambien aplica si envian desde diferentes usuarios)
El formulario sera cerrado despues del limite establecido.
Recomendaciones Finales para la entrega de los laboratorios¶
Los espacios para laboratorio son para ustedes, traten de aprovecharlos al máximo.
Es invalido enviar los laboratorios vía correo electronico y otro medio que no haya sido especificado. Se debe seguir el proceso descrito en la anterior sección.
Muy buena práctica: cuando se confirma que todos los tests están correctos, reiniciar el kernel, y dar en ejecutar todas las líneas de código. De esta manera te aseguras que todo está correcto para el envío del laboratorio.
Tener en cuenta, que si bien hay tests automáticos, los notebooks serán revisados (manera manual preguntas abiertas) y van a ser ejecutados (In notebook con errores pueden determinar una mala calficación) . Hagan los ejercicios a conciencia y con toda la dispocisión para aprender y generar habilidades.
Es muy importante revisar las guias de laboratorio con anterioridad. Es muy factible que si el primer vistazo que le hacen a la guia es durante la sesión conjunta, el tiempo no sera un aliado.
Las fechas/horas limites de entrega estan definidas. Debemos respetar las reglas para el grupo. De antemano se entienden que todos podemos tener condiciones/situaciones diferentes, sin embargo no habrá excepciones si no se siguen las pautas descritas en el estatuto estudiantíl.
# esta linea de codigo va fallar, es de uso exclusivo del los profesores
GRADER_INTRO_LAB.grade()