
Despliegue de modelos en ambientes productivos
Contents
Despliegue de modelos en ambientes productivos¶
Recordar los pasos que habíamos visto en los estándares introducidos en nuestra sesión:
Entender problema y el objetivo
Obtener y Entender los datos (análisis exploratorio– en algunas prácticas hemos iniciado con estas técnicas)
Modelar: incluyendo las transformaciones/ limpieza/ ingeniería de características de los datos y el modelo de ML (entrenamiento, validación, experimentos – lo que hemos estado haciendo en las practicas)
Despliegue del Modelo
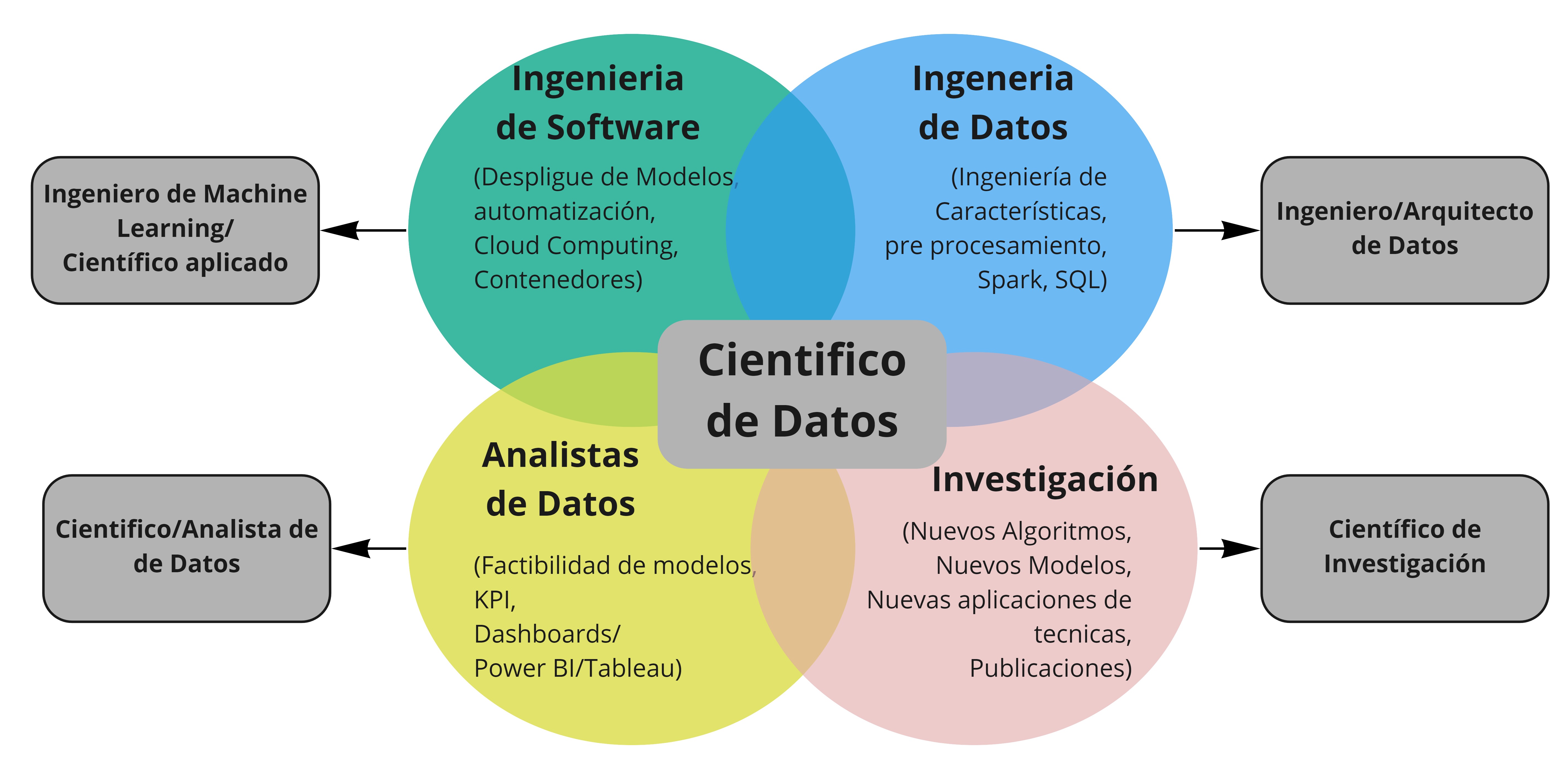
Los roles de la ciencia de Datos¶
A la hora de hablar de despliegue de modelos, nos encontramos con una discusión de roles que muchas veces se superponen. Esta superposición Se ve influenciada por diversos factores externos, como el tamaño de la compañía, el equipo y contexto particular.
Tipos de Despliegue¶
En la practica hay varios escenarios para realizar la puesta en marcha de los modelos. Como es usual depende del contexto y necesidades particulares.
Batch o por lotes¶
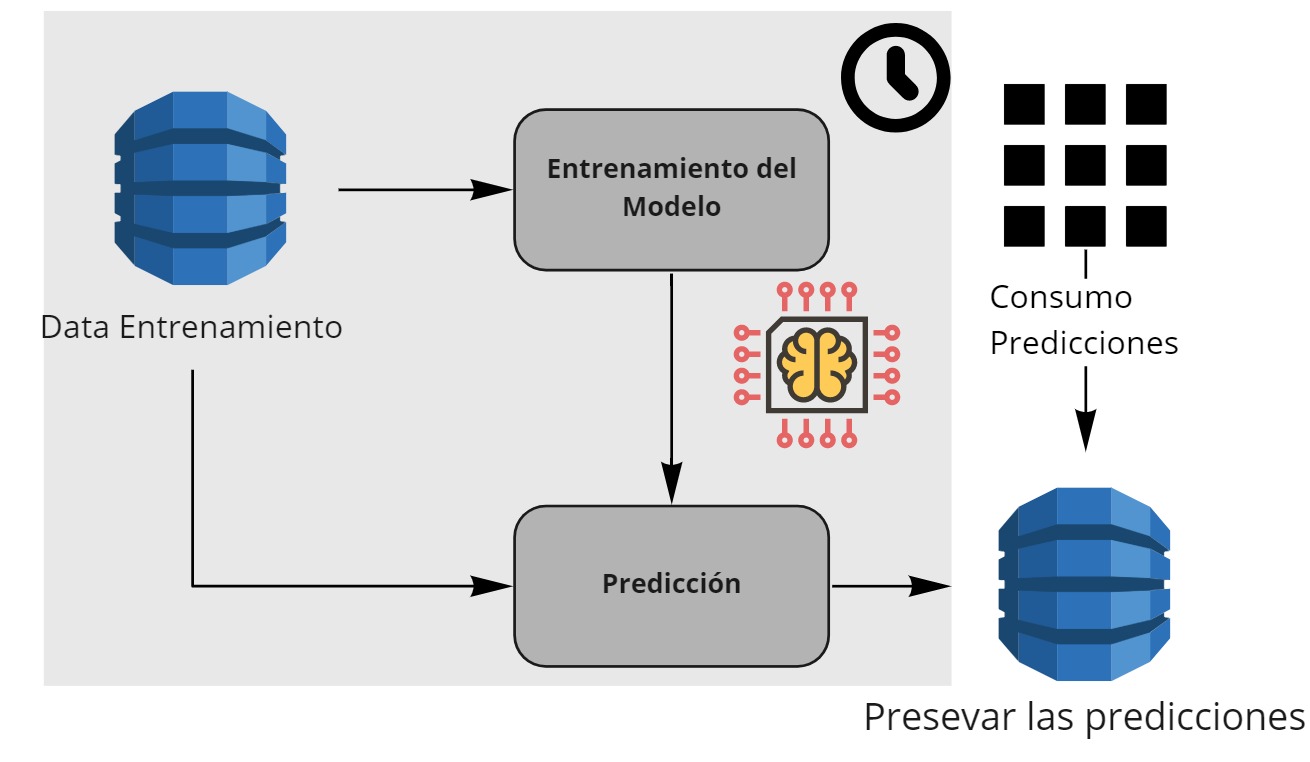
Ejemplo
Cada Trimestre una compañía de crédito, actualiza la información de sus usuarios, con esa información en la compañía predice la capacidad de pago de sus clientes. Esa predicción es almacenada y es consumida por diferentes aplicaciones y sistemas de la compañía.
Tiempo real usando Feature Lookup¶
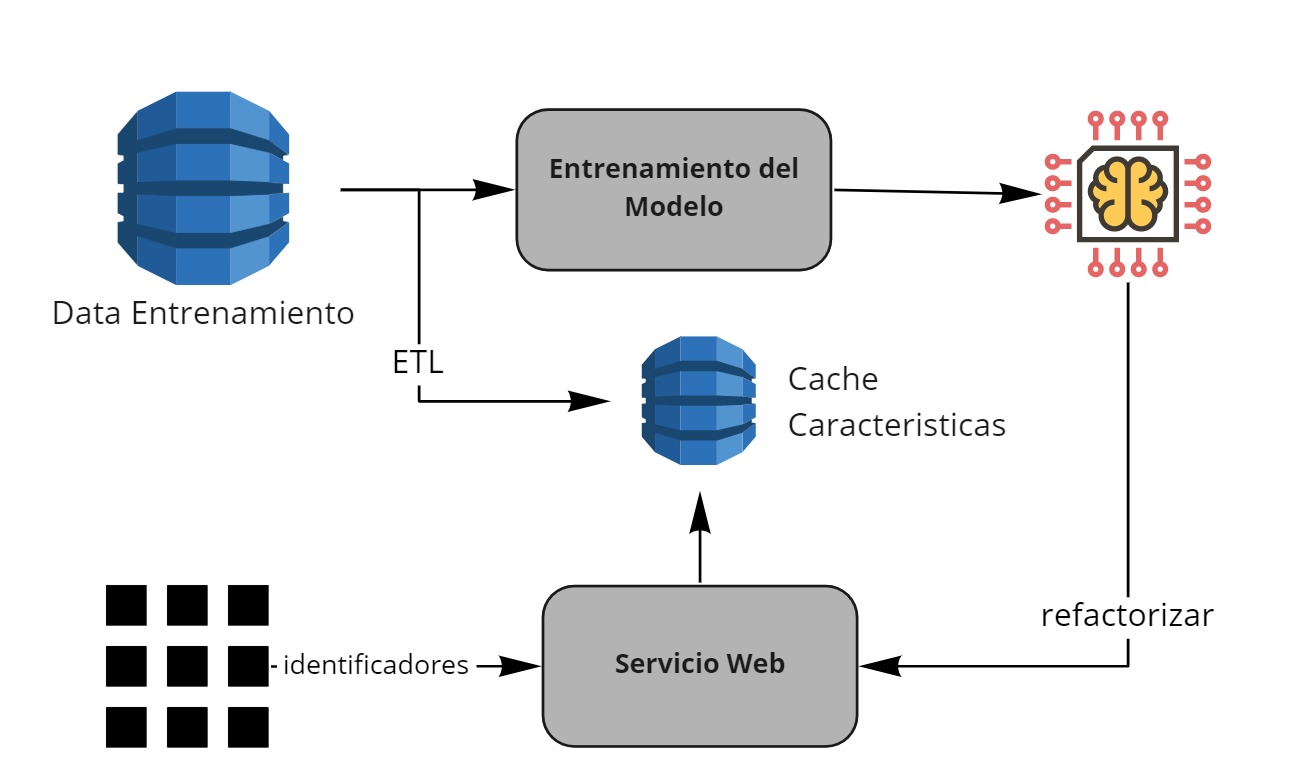
Ejemplo
Una compañía de pagos creo un modelo de predicción de fraude. El modelo necesita 100 Variables. Las 100 Variables requieren de agregaciones a nivel de usuario y otros factores.
En este caso el servicio que consume el modelo de predicción de fraude solo envía unos identificadores clave como el usuario y la tarjeta.
El modelo recibe esa información y realizar la consulta a una base de datos de cache para derivar las características. Luego de obtener las características, aplica el modelo y responde con la probabilidad de fraude.
Entrenamiento del modelo¶
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
class_names = iris.target_names
Sklearn maneja un concepto par apoder agrupar todos los pasos de procesamiento y entrenamiento del modelo.

from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())])
pipe.fit(X_train, y_train)
# probar el modelo en entrenamiento
accuracy_score(y_train, pipe.predict(X_train))
plot_confusion_matrix(pipe, X_test, y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
normalize="true")
plot_confusion_matrix(pipe, X_test, y_test,
display_labels=class_names,
cmap=plt.cm.Blues)
accuracy_score(y_test, pipe.predict(X_test))
Ahora con el modelo entrenado, persistimos el modelo.
from joblib import dump, load
dump(pipe, 'clasificador.joblib')
Importante asegurarse de la version de scikit learn
!pip show scikit-learn
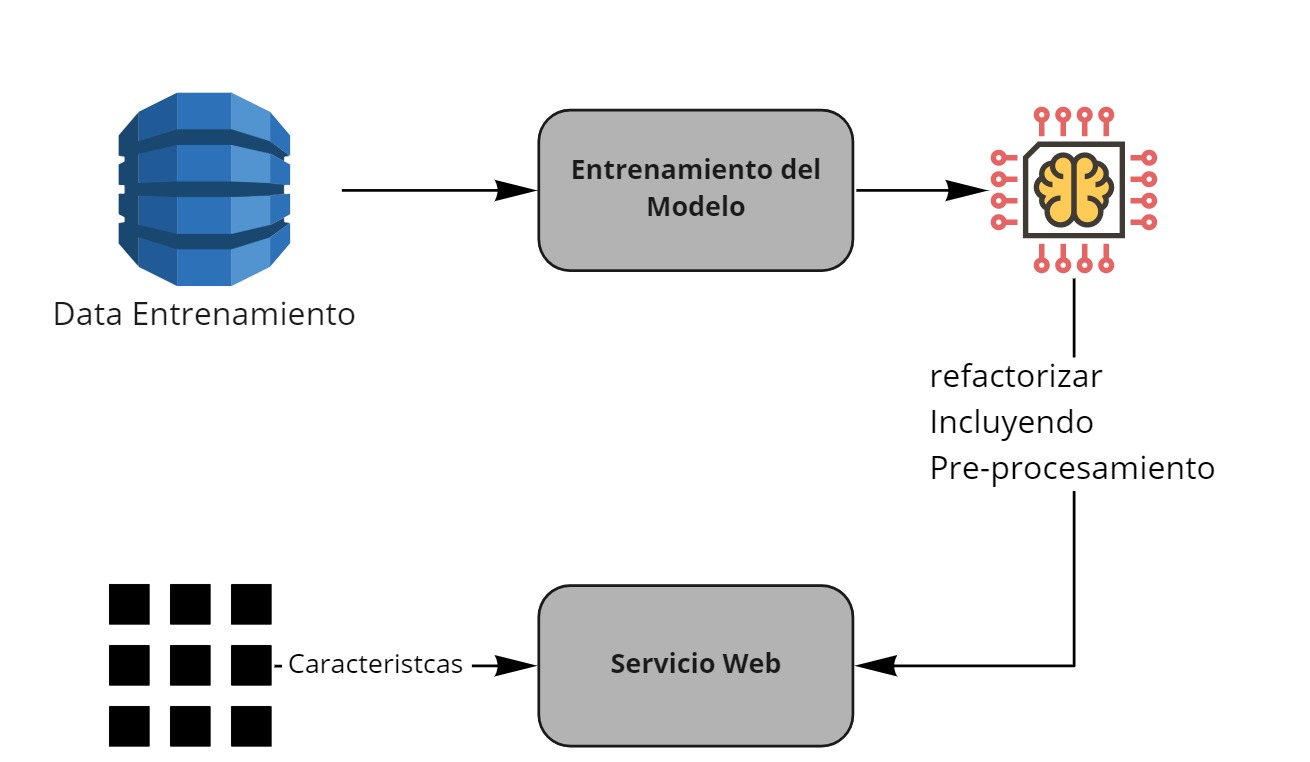
Re-factorización¶
Con el modelo ya guardado procedemos a refactorizar el proceso para poder usarlo en un servicio web. Primero probamos que podemos cargar de manera correcta el modelo y usarlo nuevamente si necesidad de entrenarlo
clf = load('clasificador.joblib')
accuracy_score(y_test, clf.predict(X_test))
Para crear el servicio web, las librerias más usadas son las siguientes:
En este sesión vamos a ver como usar Flask conjunto a otras herramientas que tienen un poco mas de profundidad.
https://www.heroku.com/ : plataforma usada para publicar servicios web.
https://git-scm.com/downloads : para gestionar el versionamiento
https://gunicorn.org/ : Servidor HTTP
¡Comencemos!
Crear un cuenta en heroku: https://www.heroku.com/. Es gratis, requiere un correo. Se recibe un correo en donde se debe confirmar la cuenta y crear la contraseña.
Instalar Heroku Cli : https://devcenter.heroku.com/articles/heroku-cli#download-and-install
Instalar Git: https://git-scm.com/downloads
Hacer login con heroku
heroku login -i
Crear una aplicación en Heroku: https://dashboard.heroku.com/apps
Crear la estructura de archivos como se muestra en esta carpeta del repositorio https://github.com/jdariasl/ML_2020/tree/master/Labs/Extra/despliegue_modelos
Vamos entender el contenido de estos archivos:
Templates: carpeta con los archivos HTML base para la aplicación
Procfile: Archivo para la configuración de Gunicorn
app.py: script con el codigo refactorizado para usar el modelo entrenado para realizar predicciones
requirements.txt: archivo especificando las dependencias
Descargar el modelo entrenado, y ponerlo en la misma estructura de carpeta a nivel del archivo
app.py. Si hay lugar modificar el nombre del archivo enapp.py.
Inicializar el repositorio git, dentro de la carpeta, reemplazar con el nombre de la aplicación creada en el paso 4.
git init
# reemplazar con el nombre de la aplicación creada
heroku git:remote -a test-ml-prd
# espeficar a heroku que se usa python
heroku buildpacks:set heroku/python
Publicar la aplicación: Adicionar los archivos, confirmar que vamos realizar el cambio y finalmente desplegarlos a la nube
git add .
git commit -am "deploying the model"
git push heroku master:main