
Preprocesamiento e Ingeniería de características
Contents
Preprocesamiento e Ingeniería de características¶
En nuestras practicas hemos tratado con información que esta relativamente lista para comenzar a crear nuestros modelos. Sin embargo en a la hora de comenzar proyectos desde cero, pocas veces nos vamos a encontrar con esta situación ideal (pero nuestros animos seguiran siendo los mismos).

*Tomada de reddit
Para comenzar estos proyectos, ada organización, equipo adapta/crea su propia metodología, aca vemos varios ejemplos referentes construidos por la industria
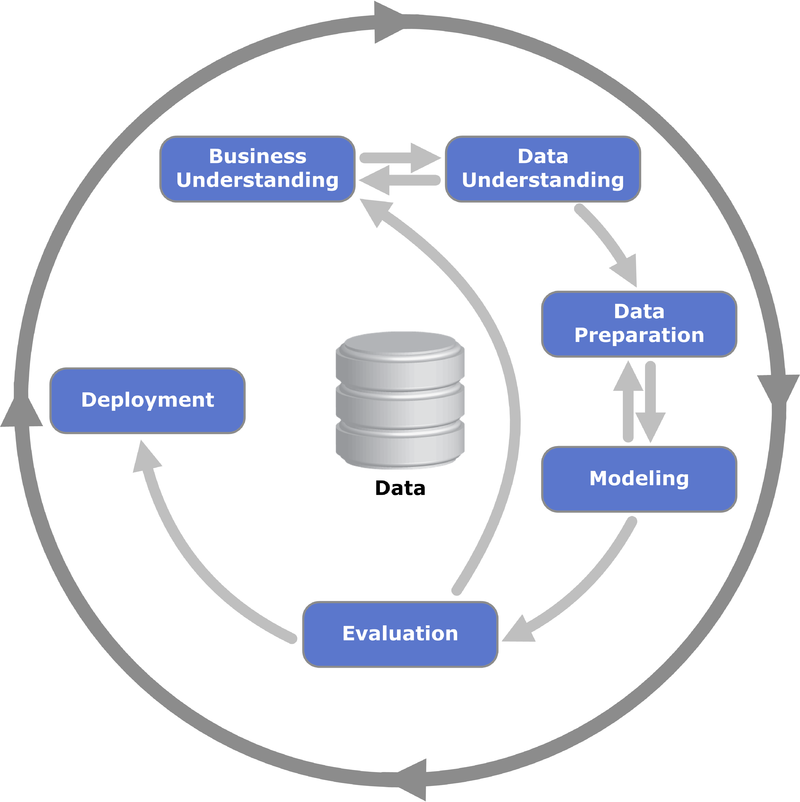
Cross Industry Standard Process for Data Mining:
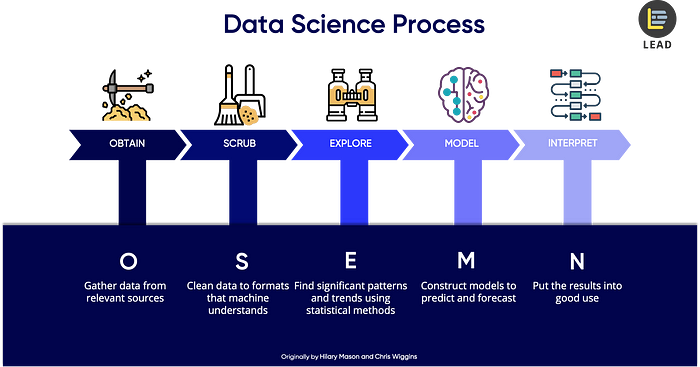
Obtaining Scrubbing Exploring Modeling iNterpret data framework**:
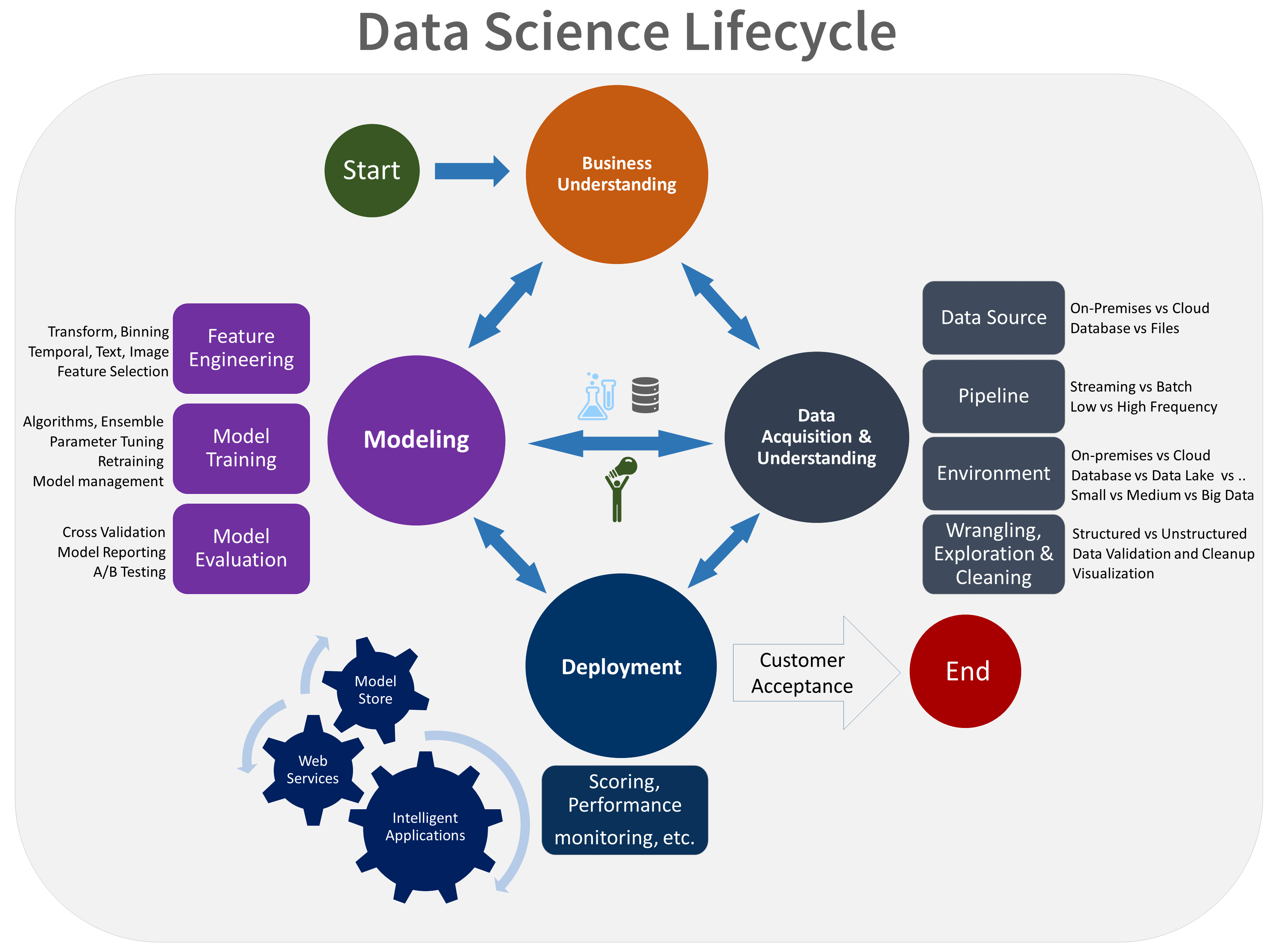
Ciclo de vida de ciencia de datos de Microsoft:
Una buena practica es no “atarse” a seguir un proceso especifico (alguna veces el proceso se repite N veces, o una etapa especifica tiene que volver hacerse en medio de otra, etc.). Lo importante es conocer las practicas y estar al tanto de algunos estandares.
La mejor recomendación de estos procesos es verlos como herramientas disponibles para los equipos. Lo importante es crear un ambiente para que el equipo tenga la libertad de aprender y aplicar cualquier practica que vea que va mejorar la calidad de trabajo entregado por el equipo.
Sin embargo, observandolos cada uno de estos procesos los podemos resumir en los siguientes pasos:
Entender problema y el objetivo
Obtener y Entender los datos(Analisis exploratorio– en algunas practicas hemos iniciado con estas tecnicas)
Modelar: incluyendo las transformaciones/ limpieza/ ingeniería de caracteriscas de los datos y el modelo de ML (entrenamiento, validación, experimentos – lo que hemos estado haciendo en las practicas)
Despliegue Modelo (nuestra segunda sesión extra)
Transformación de datos categóricos¶
Vamos a crear ciertos escenarios hipoteticos, para enfocarnos en la practica, no vamos a usar datasets o base de datos especificas.
import pandas as pd
import numpy as np
# Base de datos con datos de calificación cualtitavia
usr = ['Guido Van Rosuum','Serguéi Brin',
'Elon Musk','Alan Turing',
'Ada Lovelace', 'Richard Stallman',
'Linus Torvalds', 'Bill Gates',
'Steve Jobs', 'Margaret Hamilton',
'Yoshua Bengio']
grades = ['Excelente','Medio',
'Medio', 'Excelente',
'Excelente', 'Bajo',
'Excelente', 'Bajo', 'Bajo',
'Excelente', 'Medio']
data = {'Nombre de Usuario': usr,
'Calificación del usuario': grades,
'Calificación del publico': grades[::-1]}
data = pd.DataFrame(data)
data
# usando sklearn
from sklearn.preprocessing import OrdinalEncoder
X = data[['Calificación del usuario', 'Calificación del publico']]
enc = OrdinalEncoder()
enc.fit(X)
# ver las categorias
enc.categories_
enc.transform(X)
#asignamos a la tabla
data[['usuario_cod', 'publico_cod']] = enc.transform(X)
data
# asignar categorias para conservar el orden!!
enc = OrdinalEncoder(categories=[['Bajo', 'Medio', 'Excelente'],
['Bajo', 'Medio', 'Excelente']])
enc.fit(X)
data[['usuario_cod', 'publico_cod']] = enc.transform(X)
data
# Se puede usar para realizar transformaciones inversas (si es necesario)
# para comunicar resultados
enc.inverse_transform(data[['usuario_cod', 'publico_cod']])
# usando pandas
mapping = {'Bajo': 1, 'Medio': 2, 'Excelente': 3}
data['Calificación del usuario'].replace(mapping)
# asignar a nuevas columnas
data['usuario_cod'] = data['Calificación del usuario'].replace(mapping)
data['publico_cod'] = data['Calificación del publico'].replace(mapping)
data
La reflexión: si los datos categoricos tienen un orden/rank especifico es posible transformarlos a variables numéricas que conserven este comportamiento ordenado.
¿Que hacemos cuando los valores categoricos no tienen un orden?
ohe_data = [
{'price': 850000, 'rooms': 4, 'neighborhood': 'Queen Anne'},
{'price': 700000, 'rooms': 3, 'neighborhood': 'Fremont'},
{'price': 650000, 'rooms': 3, 'neighborhood': 'Wallingford'},
{'price': 600000, 'rooms': 2, 'neighborhood': 'Fremont'}
]
data = pd.DataFrame(ohe_data)
data
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
ohe.fit(data[['neighborhood']])
ohe.transform(data[['neighborhood']])
pd.DataFrame(ohe.transform(data[['neighborhood']]),
columns = ["ohe1", "ohe2", "ohe3"])
data = pd.concat([data,
pd.DataFrame(ohe.transform(data[['neighborhood']]),
columns = ["ohe1", "ohe2", "ohe3"])],
ignore_index = False, axis =1)
data
# Usando Pandas!
data = pd.DataFrame(ohe_data)
pd.get_dummies(data['neighborhood'], prefix='neighborhood')
df = pd.concat([data,pd.get_dummies(data['neighborhood'], prefix='neighborhood')],axis=1)
df
La reflexión: si los datos categoricos no tienen un orden/rank especifico se debe usar una codificación que no cree relaciones matematicas donde no existen. El ohe hot enconding (dummy variables) es una de las alternativas para usar valores categóricos en nuestro problemas.
Imputación de valores¶
Los valores faltantes es algo común en las bases de datos. Un buen comienzo es realizarse una seria de preugntas:
¿Hay alguna explicación del dato faltante a nivel de entendimiento del negocio?
¿Es la variable con datos faltantes vital para nuestro problema?
¿Que porcentaje de datos faltantes existen?
def generate_missing_data(rows = True, cod=False):
df = pd.DataFrame(np.random.randn(10, 3), index=range(10),
columns=['one', 'two', 'three'])
df['category'] = np.where(df['three']>0.2, "Y", "N")
df = df.reindex(range(15))
if rows:
df = df.reindex(np.random.permutation(df.index))
if cod:
df = df.where(~df.isna(), 400)
df['category2'] = 5*["Medellin", "Sabaneta", "Envigado"]
return(df)
else:
shape = df.shape
c = df['category'].copy()
values = df[['one', 'two', 'three']].values.flatten()
np.random.shuffle(values)
df = pd.DataFrame(values.reshape((shape[0], shape[1]-1)),
columns=['one', 'two', 'three'])
df['category'] = c
if cod:
df = df.where(~df.isna(), 400)
df['category2'] = 5*["Medellin", "Sabaneta", "Envigado"]
return(df)
# creacion de data de ejemplo
df = generate_missing_data()
df
# cuando hay alguna explicación y se llega a la conclusion
# de que es conveniente remover los datos faltantes
#pandas
df.dropna() # elimina datos row si encuentra un al menos una columna
df = generate_missing_data(rows=False)
df
df.dropna(subset=['two']) # elimina datos row si na en las columnas especificadas
# medir el porcentaje de datos falantes
display(df.isna())
print("")
df.isna().mean()#.round(4) * 100
Reflexión: Antes de pensar en la imputación de valores faltantes se debe analizar el impacto y tratar de buscar alguna explicación. Muchas veces la primera decisión es removerlos. Antes de pensar en la imputación, Se debe analizar el impacto de estos datos faltantes y el porcentaje.
# Cuando eliminar los datos falantes
# provoca una perdida de información importante!
# una opción es asignar un valor (no muy recomendada)
df.fillna(0.0)
# imputar valor con la media
from sklearn.impute import SimpleImputer
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
df_imp = df.copy()
df_imp[['one_imp', 'two_imp', 'three_imp']]= imp.fit_transform(df[['one', 'two', 'three']])
df_imp
# imputar valor con el valor más frequente
from sklearn.impute import SimpleImputer
imp = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
df_imp = df.copy()
df_imp[['one_imp', 'two_imp', 'three_imp', 'cat_imp', 'cat_imp2']]= imp.fit_transform(df)
df_imp
# tambien hay otras tecnicas mas sofisticadas para imputar
# datos, los cuales deben ser ajustadas
# y practicamente se vuelven un modelo
# a entrenar
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=3, weights="uniform")
df_imp = df.copy()
df_imp[['one_imp', 'two_imp', 'three_imp']]= imputer.fit_transform(df[['one', 'two', 'three']])
df_imp
# a veces la BD tiene codificado los valores faltantes
df = generate_missing_data(cod=True)
df
# recomendo transformar a valor faltante y aplicar
# tecnicas vistas
df.where(df!=400)
Otras transformaciones basicas¶
Resalatar en nuestro laboratorio hemos ya realizado transformaciones que debemos tener en cuenta:
Normalización/Estandarización: remover la media y asegurar desviación estandar 1. (
StandardScaler())Normalización asegurando un rango minimo y maximo (min-max) (
MinMaxScaler)Generación de polinomios para lograr problemas linealmente separables (
PolynomialFeatures)
Extras:
Binarización de datos: convertir variables continuas en variables categóricas https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.KBinsDiscretizer.html#sklearn.preprocessing.KBinsDiscretizer
Cuando los datos son texto (por ejemplo en procesamiento de lenguaje natural, hay transformaciones exclusivas).